

学習言語として人気が高いPython。今回はPythonを使ってWEB上の画像を取得するコードをChatGPTに書いて貰いました。
まずは簡単にPythonについて説明します!
Pythonの人気の理由は「シンプルにコードが書ける」と「ライブラリが豊富にある」です。最近では機械学習の分野にPythonが使われ一気に人気が火が付きました。求人でもPython関連は単価が高めの傾向にあります。
Pythonの基本
Pythonは学習コストが低い言語と言われています。文法も他の言語に比べ簡潔に書くことができます。これは「誰が書いても同じようなコード」にすることができ、開発においてメリットがあります。またオープンソースで情報コミュニティが多数存在するため、初学者から開発者まで幅広い層をカバーしています。
Pythonのライブラリ
Pythonが人気の理由の2つ目は様々な用途に対応したライブラリの豊富さです。Pythonで良く使用されるライブラリを紹介します。
- Pandas: データ分析と操作のための高度な機能を提供します。
- Beautiful Soup:スクレイピングに特化したライブラリ
- Matplotlib: データをグラフ化するためのライブラリです。
- Scikit-learn: 機械学習のためのシンプルで効率的なツールです。
- Requests: HTTPリクエストを簡単に送ることができるライブラリです。
Web画像スクレイピングのコード
それでは本題の画像スクレイピングです。今回は塾トップページの山本塾長の画像を取得しローカルフォルダに保存してみます。

Webスクレイピングは、ウェブサイトからデータを抽出するプロセスです。特にBeautifulSoupやRequests、Scrapyといったライブラリを使用してWebスクレイピングが行われます。以下基本的な手順です。
実行環境の構築については別途機会があれば書こうと思います。
- ページのダウンロード: requestsライブラリを使用して、スクレイピングしたいWebページのHTMLを取得します。
- データの抽出: BeautifulSoupを使用してHTMLを解析し、必要なデータを抽出します。
- データの保存:指定したフォルダ(今回はPythonコードが保存されているディレクトリ)に保存する。
※スクレイピングは著作権を侵害する可能性があります。よくサイトの規約を確認し実施してください。
<与えたスクリプト>
「Pythonを使って指定されたWEBページにある画像をスクレイピングしフォルダに保存するコードを書いて」
↓以下レスポンス
import requests
from bs4 import BeautifulSoup
def download_images(url):
# URLからページの内容を取得
response = requests.get(url)
response.raise_for_status() # ステータスコードの確認
# BeautifulSoupオブジェクトを作成してHTMLを解析
soup = BeautifulSoup(response.text, 'html.parser')
# imgタグを見つけて、画像をダウンロード
images = soup.find_all('img')
for i, img in enumerate(images):
# imgタグから画像のURLを取得
src = img.get('src')
if not src:
continue # src属性がない場合はスキップ
# URLが完全な形式かどうか確認し、必要なら修正
if not src.startswith(('http://', 'https://')):
src = url + src if url.endswith('/') else url + '/' + src
# 画像のファイル名を生成(拡張子を保持)
extension = src.split('.')[-1]
filename = f'image_{i}.{extension}'
# 画像をダウンロードして保存
img_data = requests.get(src).content
with open(filename, 'wb') as f:
f.write(img_data)
print(f"Downloaded {filename}")
# WebページのURLを指定
url = 'https://example.com'
download_images(url)
最後のurl=〇〇のところを塾サイトのURLに変更してください。
実行すると下記の様にURL内のすべての画像が取得されてしまいましたね。このコードではイメージタグを持つすべてを取得しているようです。
<保存された画像>
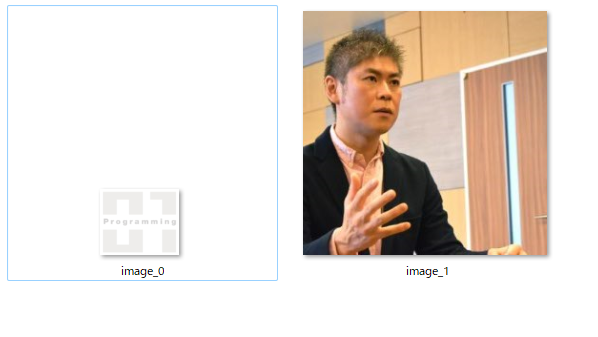
指定の画像だけ取得したいので、検証ツールから画像のタイトルを調べたところ”DSC_0514“でした。
こちらのタイトルを持つ画像を取得するようにスクリプトを追加で与えます。
<追加で与えたスクリプト>
画像をタイトルで指定する
↓以下レスポンス
import requests
from bs4 import BeautifulSoup
def download_images_by_title(url, image_title):
# URLからページの内容を取得
response = requests.get(url)
response.raise_for_status() # ステータスコードの確認
# BeautifulSoupオブジェクトを作成してHTMLを解析
soup = BeautifulSoup(response.text, 'html.parser')
# title属性が指定されたタイトルに一致するimgタグをすべて見つける
images = soup.find_all('img', title=image_title)
# 見つかった画像をダウンロード
for i, img in enumerate(images):
src = img.get('src')
if not src.startswith(('http://', 'https://')):
src = url + src if url.endswith('/') else url + '/' + src
# 画像のファイル名を生成(拡張子を保持)
extension = src.split('.')[-1].split('?')[0] # クエリパラメータを削除
filename = f'image_{i}.{extension}'
# 画像をダウンロードして保存
img_data = requests.get(src).content
with open(filename, 'wb') as f:
f.write(img_data)
print(f"Downloaded {filename}")
# WebページのURLと画像のタイトルを指定
url = 'https://example.com'
image_title = 'Specific Title'
download_images_by_title(url, image_title)
最後のURLと画像のタイトルを変更して実行してみます。
今度は指定したタイトルの画像だけ取得できました!
まとめ
ChatGPTにコードを書いてもらい指定の画像を取得することが出来ました。もっと正確にスクリプトを与えれば他の事もできそうです。
Pythonは人気のある言語です。特定のライブラリを利用することで、データ分析、ウェブ開発など、幅広い分野で活躍することができます。Webスクレイピングの技術を身につけることで、インターネット上の膨大な情報を効率的に活用することが可能になります。
面白い言語ですがプログラム言語が先行で考えず、何が適切なアプローチなのか考え言語を選択できるようにしたいですね。


